Grocery Shopping & Personality
If you’re a data fanatic like me, I like to look at Kaggle for different data sets that I can have fun with in my free time. Since starting Grad school I’ve already learned a whole bunch of great information on regression, psychometric reliability/validity, and getting aquinted with the literature. However, this post is going to be using an analysis I learned in Undergrad called the “Market Basket Analysis” (MB)
I encountered MB Analysis in my Intro to Data and Text Mining class and ever since then I’ve been trying to find ways to implement it within things I’m interested in.
There’s an old saying:
“When you have a hammer, everything looks like a nail.” - Unknown
This is very much my experience with MB analysis. I thought it was a really practical analysis.
Let’s first dive into the under the hood of MB analysis
Market Basket Analysis (MB) or Association Rules
One question you might be asking is: “Wesley, why do they call it the ‘Market Basket’ analysis?” Great question!
If we think of a market basket (or shopping cart) we have different items that we purchase throughout our visit to the store.
The main purpose of a MB analysis is to look at which items are bought together. In other words, find the association between items within a transaction.
We use association rules to mine different “if, then” statements from our data.
Let’s look at an example:
Say I have a data set in which cheese and wine are both bought together. Our algorithm will make a proposition like:
{Wine} => {Cheese}
There are 3 main types of metrics used to evaluate a proposition:
- Support
- Confidence
- Lift
Support
Support is how much an item appears in the data set.
If {Wine} has a support of 0.2, that means it occurs 20% of transactions (or shopping carts)
Formula:
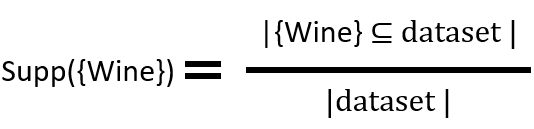
Confidence
Confidence is how often the rule is true.
If {Wine} => {Cheese} has a confidence of 0.5, that means it has been true in 50% of the shopping carts (or transactions).
Formula:
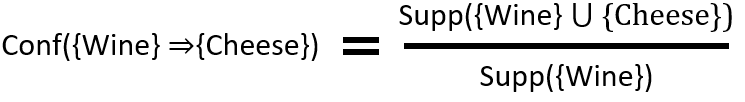
Lift
Lift is the ratio of the support to the independence of the item(s).
If {Wine} => {Cheese} has a lift of 2.5, that means it occurs 2.5 times more than if people were to just buy {Wine} itself.
Formula:
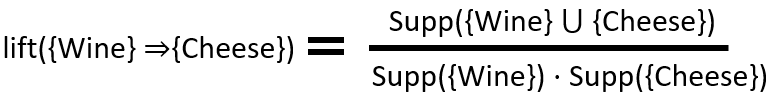
What does this have to do with personality?
Good question!
Kaggle has a data set of the Big Five Personality Test that has ~ 1 million responses to 50 questions (10 per trait).
Let’s take a step back and abstract MB & the BFI Personality test.
Imagine we are in a shopping plaza. There are 5 stores, each for the different personality traits. (Extraversion store, Openness store, …)
I go to the Extraversion store and go through the 10 different aisles and pick out 1 unique item per aisle.
We can use MB analysis to look at my shopping cart for each store I go to.
Let’s start coding
library(arules) # Association Rules
library(dplyr)Load in data:
(I sampled the original data set for the purpose of this post; n = 1000)
sampled_data <- readr::read_csv(
here::here(
"content",
"post",
"2021-09-08-arules_mining",
"sampled_data.csv"
)
)Taking a look at our data:
knitr::kable(head(sampled_data))| id | EXT1 | EXT2 | EXT3 | EXT4 | EXT5 | EXT6 | EXT7 | EXT8 | EXT9 | EXT10 | EST1 | EST2 | EST3 | EST4 | EST5 | EST6 | EST7 | EST8 | EST9 | EST10 | AGR1 | AGR2 | AGR3 | AGR4 | AGR5 | AGR6 | AGR7 | AGR8 | AGR9 | AGR10 | CSN1 | CSN2 | CSN3 | CSN4 | CSN5 | CSN6 | CSN7 | CSN8 | CSN9 | CSN10 | OPN1 | OPN2 | OPN3 | OPN4 | OPN5 | OPN6 | OPN7 | OPN8 | OPN9 | OPN10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 664928 | 3 | 2 | 4 | 2 | 3 | 2 | 3 | 2 | 3 | 3 | 2 | 4 | 3 | 2 | 4 | 3 | 2 | 2 | 2 | 2 | 2 | 4 | 1 | 3 | 3 | 4 | 2 | 4 | 4 | 4 | 3 | 2 | 3 | 2 | 3 | 2 | 3 | 3 | 4 | 3 | 3 | 2 | 3 | 3 | 4 | 1 | 4 | 3 | 3 | 4 |
| 814515 | 3 | 1 | 5 | 2 | 4 | 1 | 4 | 2 | 5 | 2 | 4 | 4 | 2 | 3 | 2 | 3 | 4 | 4 | 4 | 3 | 2 | 4 | 1 | 2 | 3 | 5 | 2 | 4 | 3 | 3 | 3 | 5 | 2 | 2 | 2 | 3 | 4 | 3 | 3 | 3 | 3 | 1 | 3 | 2 | 3 | 1 | 4 | 1 | 2 | 3 |
| 911060 | 2 | 3 | 3 | 4 | 3 | 3 | 3 | 4 | 2 | 4 | 3 | 3 | 4 | 3 | 3 | 4 | 3 | 3 | 4 | 3 | 1 | 4 | 2 | 5 | 2 | 4 | 2 | 4 | 4 | 3 | 4 | 1 | 4 | 2 | 4 | 2 | 4 | 3 | 4 | 4 | 3 | 4 | 2 | 1 | 3 | 3 | 3 | 3 | 3 | 2 |
| 358416 | 3 | 2 | 2 | 4 | 2 | 2 | 2 | 3 | 2 | 3 | 4 | 3 | 4 | 1 | 4 | 4 | 4 | 4 | 5 | 4 | 2 | 3 | 4 | 4 | 3 | 4 | 2 | 4 | 3 | 3 | 3 | 2 | 3 | 2 | 2 | 4 | 4 | 3 | 3 | 3 | 4 | 2 | 5 | 1 | 5 | 2 | 4 | 3 | 4 | 4 |
| 689863 | 3 | 3 | 3 | 3 | 4 | 2 | 4 | 2 | 4 | 3 | 1 | 4 | 4 | 3 | 1 | 4 | 3 | 2 | 3 | 3 | 2 | 4 | 1 | 5 | 1 | 3 | 3 | 4 | 5 | 4 | 5 | 2 | 4 | 1 | 1 | 2 | 4 | 3 | 5 | 5 | 3 | 4 | 3 | 2 | 3 | 4 | 5 | 3 | 4 | 2 |
| 648593 | 2 | 3 | 4 | 3 | 4 | 2 | 3 | 3 | 3 | 4 | 4 | 2 | 5 | 2 | 4 | 4 | 4 | 4 | 4 | 4 | 1 | 4 | 2 | 5 | 1 | 5 | 2 | 4 | 4 | 4 | 4 | 3 | 4 | 2 | 2 | 2 | 4 | 2 | 4 | 4 | 4 | 2 | 2 | 2 | 3 | 4 | 5 | 4 | 4 | 2 |
Reverse Score
Since we are looking at the responses themselves we need to reverse code the negative items.
neg_questions <- c(
"EXT2", "EXT4", "EXT6", "EXT8", "EXT10", # 5
"EST2", "EST4", # 2
"AGR1", "AGR3", "AGR5", "AGR7", # 4
"CSN2", "CSN4", "CSN6", "CSN8", # 4
"OPN2", "OPN4", "OPN6" # 3
)
sampled_datar <-
sampled_data |>
mutate(across(where(is.numeric), ~ as.character(.x))) |>
mutate(across(all_of(neg_questions), ~ dplyr::recode(.x,
"5" = "1",
"4" = "2",
"3" = "3",
"2" = "4",
"1" = "5")))Careless Responses
When looking at psychometric data it is usually a good idea to implement some sort of removal of careless responses. To do that we can implement 2 simple methods: Long-String and Intra-individual response variability (IRV).
find_longeststring <- function(row_of_data){
dat_rle <- rle(row_of_data)
longest_string <- max(dat_rle$lengths)
return(longest_string)
}
find_longstring_avg <- function(row_of_data){
dat_rle <- rle(row_of_data)
longest_string_avg <- mean(dat_rle$lengths)
return(longest_string_avg)
}Let’s remove our careless responses
# Calculate Long-String and IRV
careless_data <-
sampled_datar |>
rowwise() |>
mutate(
longest_string = find_longeststring(c_across(EXT1:OPN10)),
avg_longstring = find_longstring_avg(c_across(EXT1:OPN10)),
irv = sd(c_across(EXT1:OPN10))
) |>
ungroup() |>
mutate(
scaled_ls = scale(longest_string),
scaled_avg_ls = scale(avg_longstring),
scaled_irv = scale(irv)
)
## Cut off value of 2 standard deviations
long_string_excluded <-
careless_data |>
filter(scaled_ls <= 2) |>
filter(scaled_avg_ls <= 2) |>
filter(scaled_irv >= -2)As we can see we are left with 962 results vs 1000 (removed 3.8%)
A little bit of wrangling
Now, one cavet to the algorithm we are going to be using today (the apriori()) is each item needs to be unique in each cart. Not only that, but the function requires a specific format of data.
To do this I am going to factorize each item as such:
q= question number (1-10)a= answer (1-5)
factorize_item <- function(aisle_number, aisle_item){
item_factor <- paste0("q", aisle_number,"_" ,"a", aisle_item)
return(item_factor)
}The Extraversion Store
ext_store <-
long_string_excluded |>
select(EXT1:EXT10)
# Since I was working with sample data
# I noticed sometimes I would get "NULL"
# values, so if you run into that in your
# own analysis:
ext_store <-
ext_store |>
filter(
across(
.cols = everything(),
.fns = ~ !stringr::str_detect("NULL", .x)
)
)Using map_dfr() we can apply to our Extraversion Store.
for (i in 1:10) {
ext_store[,i] <- purrr::map_dfr(.x = ext_store[,i], ~ factorize_item(i, .x))
}Let’s take a look:
knitr::kable(head(ext_store))| EXT1 | EXT2 | EXT3 | EXT4 | EXT5 | EXT6 | EXT7 | EXT8 | EXT9 | EXT10 |
|---|---|---|---|---|---|---|---|---|---|
| q1_a3 | q2_a4 | q3_a4 | q4_a4 | q5_a3 | q6_a4 | q7_a3 | q8_a4 | q9_a3 | q10_a3 |
| q1_a3 | q2_a5 | q3_a5 | q4_a4 | q5_a4 | q6_a5 | q7_a4 | q8_a4 | q9_a5 | q10_a4 |
| q1_a2 | q2_a3 | q3_a3 | q4_a2 | q5_a3 | q6_a3 | q7_a3 | q8_a2 | q9_a2 | q10_a2 |
| q1_a3 | q2_a4 | q3_a2 | q4_a2 | q5_a2 | q6_a4 | q7_a2 | q8_a3 | q9_a2 | q10_a3 |
| q1_a3 | q2_a3 | q3_a3 | q4_a3 | q5_a4 | q6_a4 | q7_a4 | q8_a4 | q9_a4 | q10_a3 |
| q1_a2 | q2_a3 | q3_a4 | q4_a3 | q5_a4 | q6_a4 | q7_a3 | q8_a3 | q9_a3 | q10_a2 |
Now that I have that I just need to combine every row into it’s own basket.
ext_store_b <-
ext_store |>
mutate(basket = paste(EXT1,EXT2,EXT3,EXT4,EXT5,
EXT6,EXT7,EXT8,EXT9,EXT10,
sep = ","))
baskets <-
ext_store_b |>
select(basket)The apriori() function requires a specific data structure. The code below isn’t pretty but it does the trick!
transaction_list <-
list()
for (i in seq_along(1:nrow(baskets))) {
counter <- 1
row <- as.character(ext_store[i,])
transaction_list[[i]] <- c(row[counter],row[counter+1],row[counter+2],
row[counter+3],row[counter+4],row[counter+5],
row[counter+6],row[counter+7],row[counter+8],
row[counter+9])
}
names(transaction_list) <- paste("Tr",seq_along(1:nrow(ext_store)), sep = "")
transaction_obj <- transactions(transaction_list)Now that we have our data in the right format, we can create our rules.
m1 <- apriori(transaction_obj,
parameter = list(support = 0.007,
confidence = .95,
minlen = 2))## Apriori
##
## Parameter specification:
## confidence minval smax arem aval originalSupport maxtime support minlen
## 0.95 0.1 1 none FALSE TRUE 5 0.007 2
## maxlen target ext
## 10 rules TRUE
##
## Algorithmic control:
## filter tree heap memopt load sort verbose
## 0.1 TRUE TRUE FALSE TRUE 2 TRUE
##
## Absolute minimum support count: 6
##
## set item appearances ...[0 item(s)] done [0.00s].
## set transactions ...[50 item(s), 962 transaction(s)] done [0.00s].
## sorting and recoding items ... [50 item(s)] done [0.00s].
## creating transaction tree ... done [0.00s].
## checking subsets of size 1 2 3 4 5 6 7 8 9 done [0.01s].
## writing ... [1470 rule(s)] done [0.00s].
## creating S4 object ... done [0.00s].rules_df <- DATAFRAME(m1) |>
mutate(LHS = as.character(LHS),
RHS = as.character(RHS))Let’s look at the results
t <- rules_df |>
filter(!stringr::str_detect(RHS, "a1")) |>
filter(!stringr::str_detect(RHS, "a5"))
knitr::kable(head(t))| LHS | RHS | support | confidence | coverage | lift | count |
|---|---|---|---|---|---|---|
| {q10_a4,q4_a3,q7_a4} | {q5_a4} | 0.0083160 | 1 | 0.0083160 | 3.498182 | 8 |
| {q10_a4,q3_a5,q7_a2} | {q1_a3} | 0.0083160 | 1 | 0.0083160 | 3.460432 | 8 |
| {q1_a4,q2_a3,q5_a3} | {q4_a3} | 0.0072765 | 1 | 0.0072765 | 3.894737 | 7 |
| {q10_a3,q2_a2,q6_a4} | {q3_a4} | 0.0072765 | 1 | 0.0072765 | 3.657795 | 7 |
| {q2_a2,q7_a1,q9_a4} | {q4_a2} | 0.0072765 | 1 | 0.0072765 | 3.772549 | 7 |
| {q3_a2,q5_a4,q8_a2} | {q4_a2} | 0.0072765 | 1 | 0.0072765 | 3.772549 | 7 |
References
Saltz, J. S., & Stanton, J. M. (2018). An introduction to data science (First edition). SAGE.
Wesley Gardiner
I-O Psychology Graduate Student
My primary research interests include personality, psychometrics, and teams.